Chatbot
 Sample dialogue
Sample dialogueEver since the Turing test was formulated by Alan Turing in 1950, ever more sophisticated chatbots were created for both commercial and research applications. In the context of recent advances in Natural Language Processing (NLP) modern chatbots are increasingly more accurate at inferring and addressing user’s query on a large variety of topics. While state-of-the-art systems, such as IBM Watson, can be incredibly sophisticated, most chatbots share basic building blocks that perform a set of simple functions. The chatbot I developed demonstrates how some of these basics blocks work together to find a code-related query through a casual conversation and provide the user with a relevant link to stackoverflow thread.
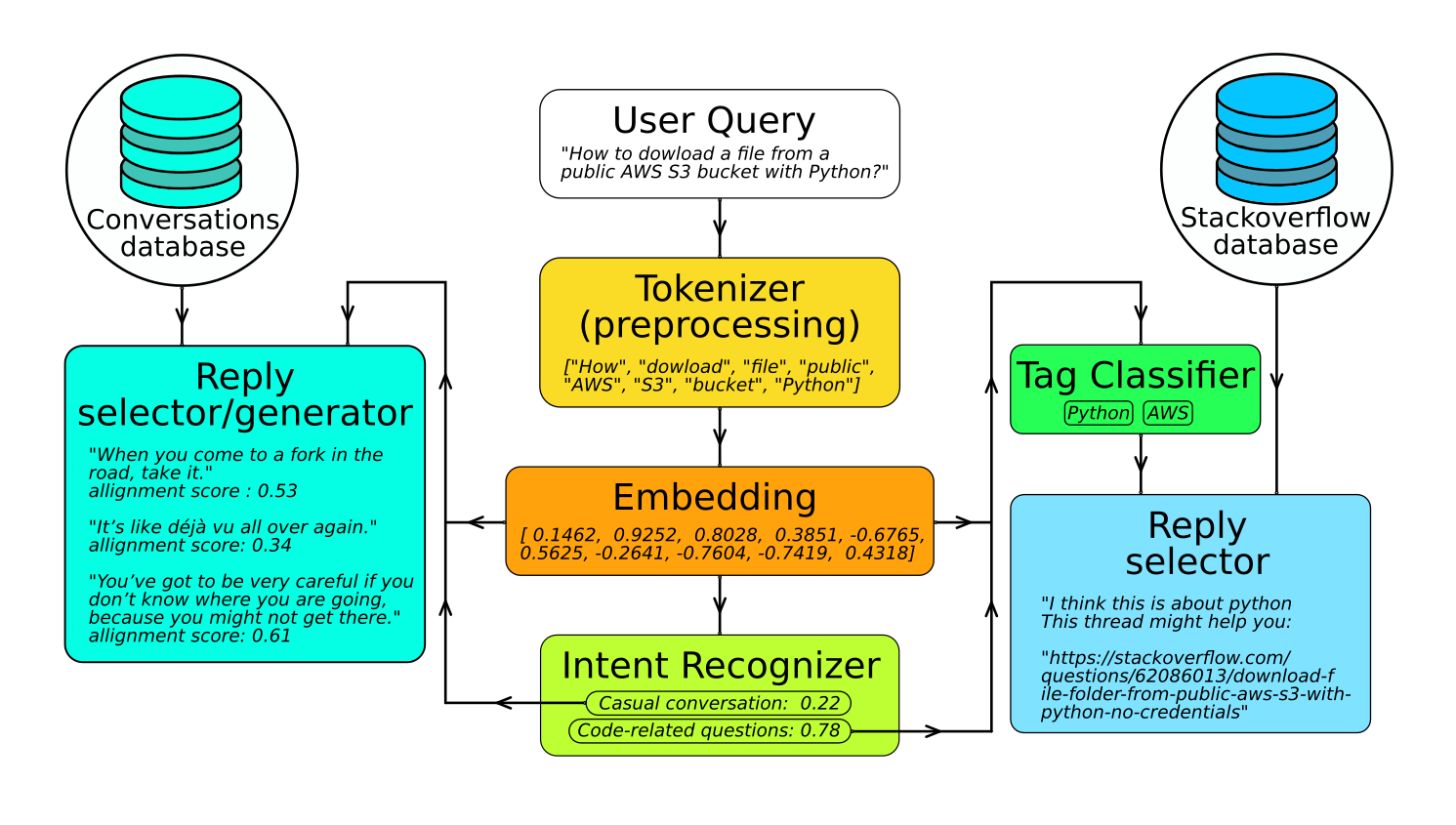
The objective of the chatbot is to pick up a software related question, suggest a relevant thread from stackoverflow, while been able to support a casual conversation. This requirement determines the first step, where a decision must be made if the User Query is a software-related question, or a part of a casual conversation. If the User Query is determined to be a part of a casual conversation, it is handled by a conversation agent. Otherwise, the software related question it is classified again to determine the relevant tags. This is followed by comparison to all question texts of stackoverflow threads from the relevant tag subset.
Preprocessing and tokenization include converting the query string to lower case and removal of punctuation. Stop words from the NLTK library dictionary are also removed. The simplest word embedding is a large lookup table. Each row corresponds to the word from a dictionary that is determined from the training dataset. The columns represent real numbers, which together form a vector representation of the word. Check out my TDS article, where I explore a whole text embedding using RoBERTa, state-of-the-art NLP model, developed by Google. In this chatbot embeddings and intent classification are performed with Scikit-learn library. The intent classification achieves 99% accuracy. Software-related queries are compared to pre-calculated embeddings of stackoverflow question texts from a tag subset using cosine similarity metric. The tag subset is selected via an additional tag classification step, which achieves an accuracy of 80%.
The casual conversation branch of the chatbot is implemented using a ChatterBot library. It was trained on Cornell Movie Dialogue Corpus and the Chatterbot native corpus. A special pre-computed word embedding, obtained using Facebooks StarSpace package, was used for conversation branch (not depicted in the diagram) instead of embedding from the intent classification branch. This has significantly improved the quality of casual conversation replies.
In summary, this project demonstrates several essential components of modern chatbots and how they work together. Online version of the program was deployed using Amazon Web Services Elastic Cluster. The local version of the chatbot is available at my GitHub repository. The simplest way to run the bot is by using Docker or Docker-compose and instructions in the repository description.